
Much like my previous post on Kaktovik numerals, this post is about doing things on paper in a visual way. So, if you rely on non-visual means, like screen readers… there’s not much useful stuff for you. Sorry.
So I was looking for a good shorthand / stenography system. Preferably multi-lingual, so that I can write both English and Russian / Interslavic. I searched far and wide for Armenian stenography systems. Because Armenian phonetics is almost a superset of Russian and English. So if I can write Armenian shorthand, I can write English and Russian easily. But no, there’s no Armenian shorthand documented anywhere. (Update: there seems to be one!) Even in the biggest library of Armenia. Only Russian-language systems, like GESS.
So GESS (‘gosudarstvennaja ědinaja sistema stenografiji’, unified state system for stenography) is this stenography / shorthand system. A way to write really fast using a simplified alphabet. Devised by Nikolai Sokolov in the beginning of last century. And chosen as the standard for stenography in USSR. Interestingly enough, it was explicitly stated as incomplete, but was chosen literally anyway. Soviet moment, I GESS (sorry.)
There were some improvements / developments, starting with ’39 version, then ’67 version, then Jakov Každan’s 1991 version.
Here I focus on Sokolov’s ’39 version and Každan’s version, picking the best parts from either.
Mostly because these were the ones I found textbooks for.
(Contact me if you want me to share!)
A rivaling standard was Oganes Akopyan’s (Hakobyan’s) system.
Supposedly simpler and faster.
But there’s literally no materials on this system on the Internet.
And there’s only one book on it in National Library of Armenia.
There’s also
Polish Gregg adaptations,
and likely Russian too.
But these are inherently English-centric and not tailored to the language.
So GESS it is.
(One can say that Sokolov’s GESS is actually a rehash of
Gebelsberger’s system.
But this adaptation is still better than Gregg, because it was tested on Polish and Czech with reasonable success.)
Note that this post / set of notes focuses on Russian-oriented stenography system. So most resources are either in Russian or focus strongly on Russian. They can be applied to Interslavic, and that’s one of the focus areas for me. I’m trying to keep things in English most of the time, but the topic is inherently non-English.
Speaking of Interslavic, most of the Russian words in this post will be transliterated by the rules of Interslavic:
In case you don’t know Cyrillic script, this constructed Cyrilice script maps Cyrillic letters to Czech / Interslavic / Latinized letters.
I have to applaud Každan’s book for a nice format, reasonable improvements (with significant exceptions,) and good reference material.
In particular, the first two pages of the book give a cheat sheet for the whole system succintly:
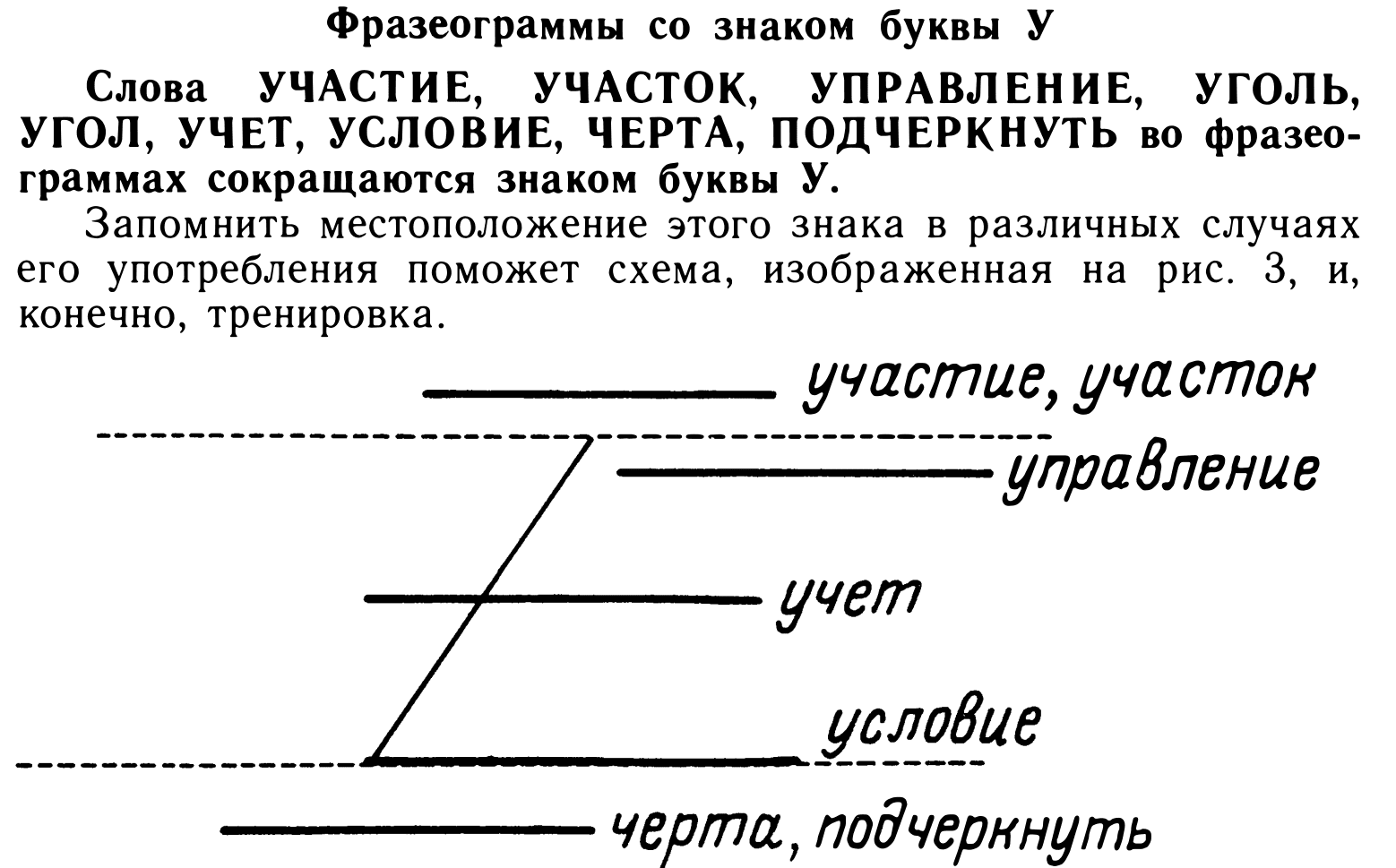
This alphabet improves over Sokolov’s one by using smaller symbols.
Sokolov’s one used these, often bloating the size of the line:
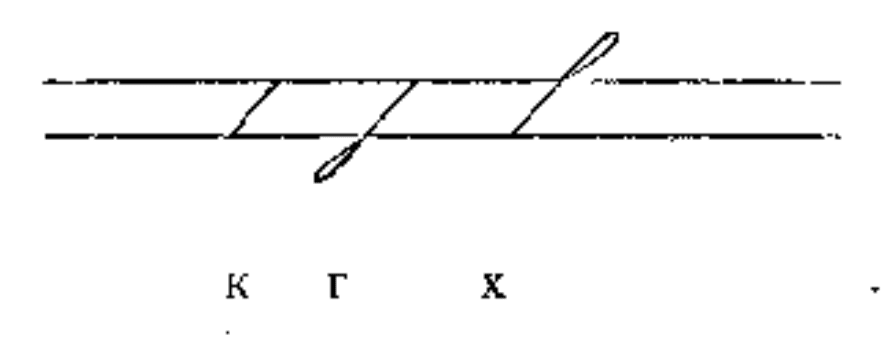

So most of the consonants are vertical and starting from the upper line or between lines. And end on the lower line, almost unconditionally. (By the way, upper line is called “control line” and the lower one is called “base line.”) Which means they can be trivially chained together by means of a small upward stroke (“alphabetic stroke” they call it.)
Vowels are expressed as diagonal and horizontal strokes. a/ja doesn’t have a dedicated middle-of-the-word stroke, merely being implied in alphabetic stroke. (Wait, it actually does!) Because “a” is the most frequent vowel in Russian.
In Sokolov’s GESS every vowel has a dedicated stroke, most of them barely distinguishable from each other. But the benefit of that is that it allows transcribing with exactness, important for transcribing names. But still—annoying number of similar strokes. Každan improves over that, merging “a” with “ja,” “i” with “y,” “ě” with “e” and “jo,” (should have been merged with “o”?) and “u“ with “ju.” Which makes decoding stenograms harder, but makes learning and recording easier. Which matters slightly more, because that’s the most intensive part of stenography.
While consonants have simple connections between each other, vowels introduce some chaos. Because vowels raise and lower the following consonants. In particular,
This results in a wobbly type of writing, jumping up and down. For Russian, this is mostly okay, because most frequent vowel—“a”—does not raise or lower things, while the second most frequent—“ě”—lowers things. Which balances out the radical raise “i” introduces.
There’s also a “linearity rule” explained by both Sokolov (in detail) and Každan (in passing.) Helping one to keep things on one line. In short, it allows perceiving “o“ in the middle of the word as “a.” And lowering consonant clusters where unambiguous. They frame it more elaborately, but this version is what I’m using.
Both Sokolov and Každan introduce a lot of shortcuts.
Ranging from simple letter combinations to full words.
The former are useful for Russian due to shortening frequent patterns.

I don’t like “str” and “tr” signs, because they break the flow of writing, turning it into right-to-left that’s hard to recover from. But I might change this opinion with practice.
Another type of shortcuts are frequent prefixes and particles:

I like the upper two lines, while the lower two are too symbolic and hard to remember for my taste.
Then there are word shortcuts, and these suck.
Most are socialist-specific and woefully outdated.
Here’s the most exemplary one:
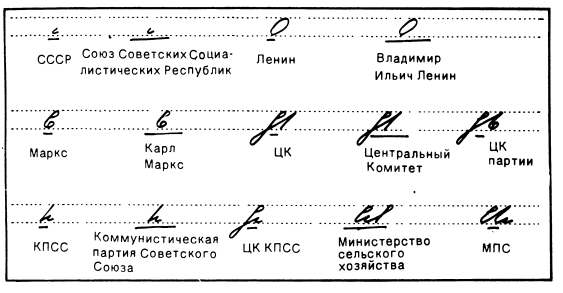
Believe me, the other ones are not better.
Sokolov’s are somewhat better:

There’s barely a handful of useful abbreviations and shortcuts besides that:
I’ll probably come up with some more based on my own writing. Which is, like, what personal stenography about anyway?
There also are useful pronoun shorteners:

There’s a bunch of symbolic shorthands too, abstracting many frequent (to a Soviet person) words:

A lot of word endings are abbreviated to a single / couple of letters. Convenient for Russian where there is a lot of similar endings.
Some endings, like -y for adjectives, are left out altogether when unambiguous. Like when they are followed by a conjugated noun.
For the other cases, I’ll just list images here

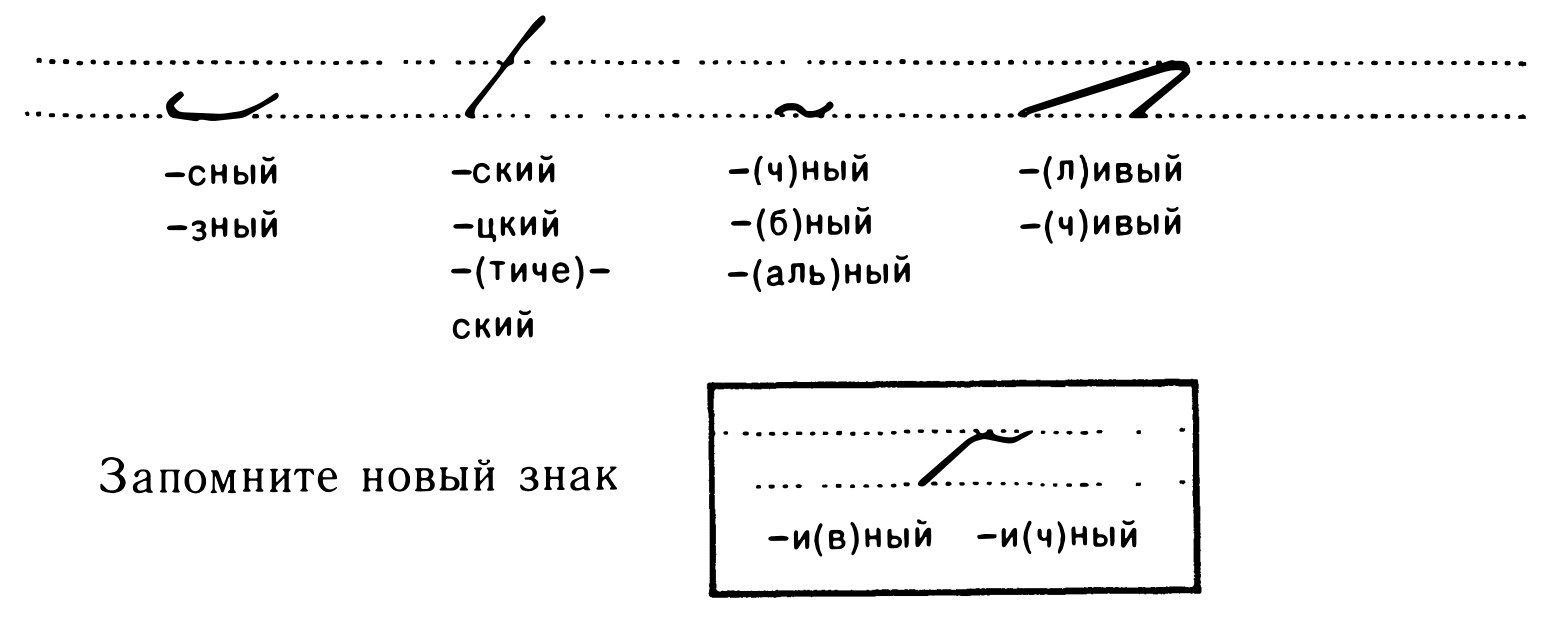

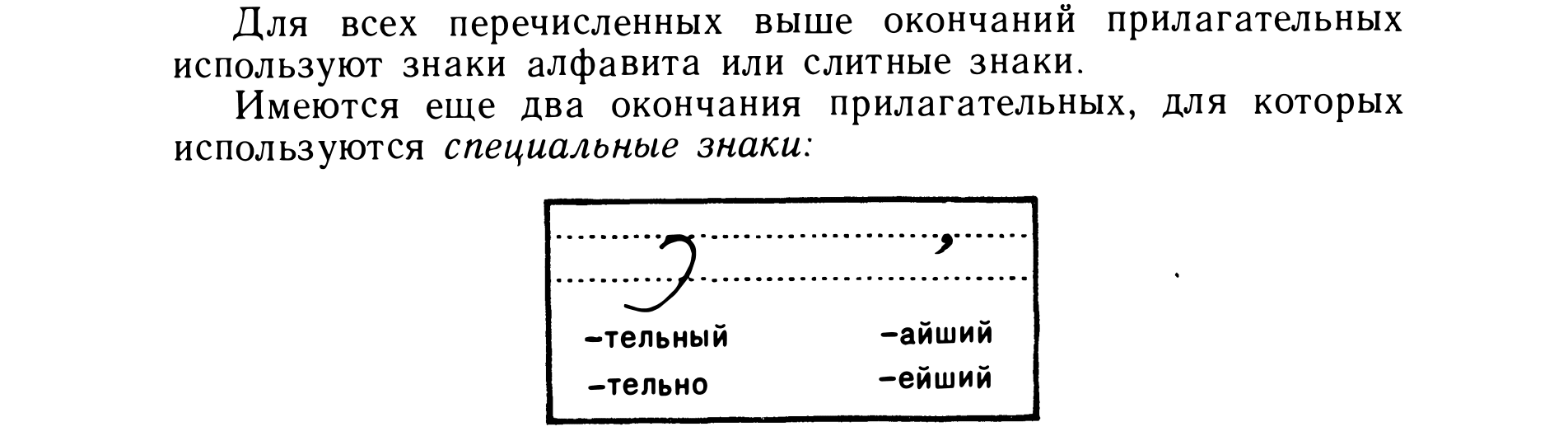
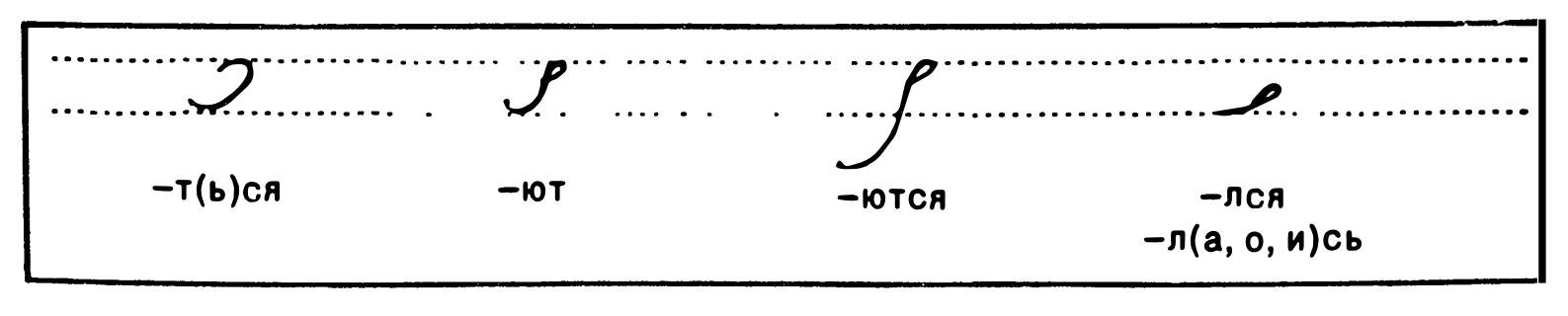
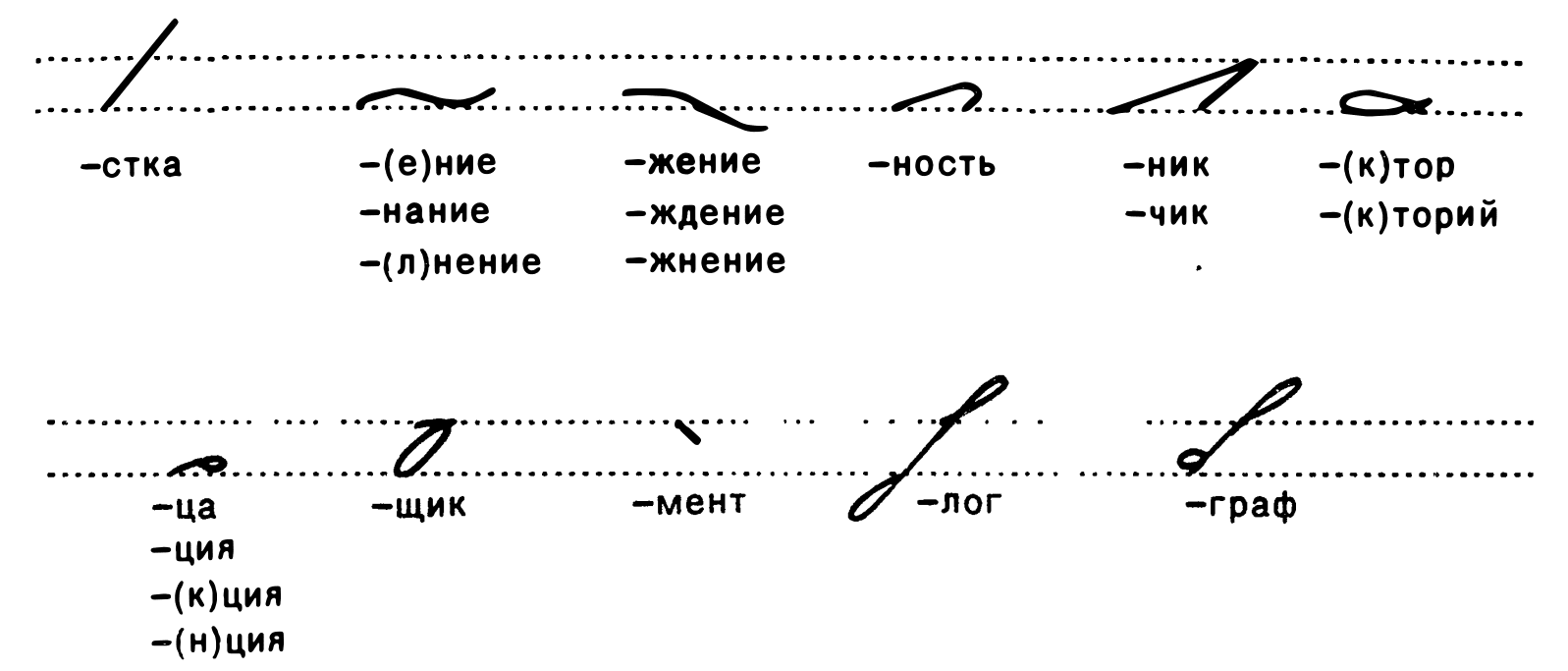

Some more endings
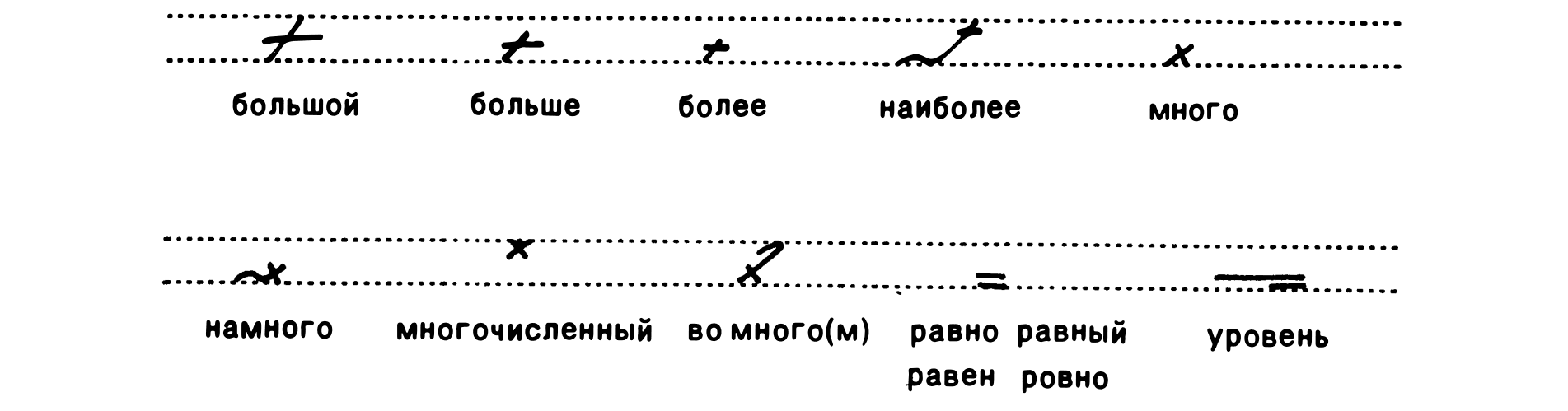
Numbers are written pretty much the same in GESS as in cursive.
Just slightly more optimized.

There’s also a bunch of shortcut symbols related to numbers and calculation. I’ll list them without explaining, sorry:



Každan mentions it in passing, but I personally find it quite important: There still is punctuation in stenography. And it’s exactly the same as in cursive / longhand! So unoptimized.

So I decided to optimize this and strike a simple dash for period and double dash (= equals sign) for question mark. Given that I don’t use Každan’s horrible positional abbreviations, a lone dash in the middle of the line is free for interpretation.
I use the hook dash from above, though. And—no other punctuation. Only period— question mark— and dash. Because these are enough to bootstrap almost any text from. As Lu Wilson shows— dashes are quite versatile in expressing things. So I’m fine with all my texts having—uhmmmm—dashes for commas and other punctuation. Especially for spoken word—where there only are pauses. If you think in these terms—and in general in stenographing terms—then you notice the pause patterns in speech being—basically—indistinguishable. Commas are literary devil’s invention.
Okay, dash-only experiment wrapped up, back to fancy punctuation. Parens and brackets are fine, as they are much rarer than either terminators or pauses. I tend to make parens really huge to not confuse them with other strokes. I also use Japanese quotation marks as the most distinguishable of quotation syntaxes. And interpunct (·) for enumerations—the only case where dash is too overloaded to use. (Did I tell you I love lists?) But, again, I rarely have to use all of these, so it’s fine if they are unoptimized.
Oh, right, apostrophe! Many contractions in English use it. I simply don’t write it, but add a small gap in place where apostrophe was. So the word looks almost complete and one-stroke, but actually isn’t. This is enough to mark apostrophe and retain readability. Nice!
English is not Russian at all. Which shows in systems like Forkner, which are phonetic and not alphabetic. So if I want to use GESS for English, I’d better switch to phonetics. Essentially writing transliterated English in Russian. Which is not a 1-to-1 mapping, but better than using (reductionist) Forkner or Gregg for Russian.
But using GESS for English means most shortcuts become useless. We need to come up with some more. I’m going to rely on Forkner shortcuts to derive Transliterated GESS versions.
Changing the “default” alphabetic connection to mean “e” instead of “a” might be a good move. After all, Forkner uses the alphabetic stroke for “e,” as the most frequent sound.
Then one would need to represent “a” somehow. And there is such a way, using alternative “a” sign. Or maybe use “e” stroke for “a?”
I’m indecisive though. Changing something as fundamental as default vowel is a lot. So maybe I’m better off with explicit “e” and default “a” instead? This would mean slight downward drift for words. But English is on average shorter than Russian, so no big deal.
There are not many:
While the mapping between English w and GESS v / u bit me more than once already. And so did mapping for thorn. I still think it a decent mapping for what it’s worth.
So NLTK, natural language toolkit for Python. Classifies words by endings. Which is useful for me adding my own ending shorthands!
MORPHOLOGICAL_SUBSTITUTIONS = {
NOUN: [
("s", ""),
("ses", "s"),
("ves", "f"),
("xes", "x"),
("zes", "z"),
("ches", "ch"),
("shes", "sh"),
("men", "man"),
("ies", "y"),
],
VERB: [
("s", ""),
("ies", "y"),
("es", "e"),
("es", ""),
("ed", "e"),
("ed", ""),
("ing", "e"),
("ing", ""),
],
ADJ: [("er", ""), ("est", ""), ("er", "e"), ("est", "e")]\,
ADV: [],
}
Having that, we can derive shortcut endings:
Then, abbreviations, taken from Forkner Shorthand book:
There are many other sets of abbrevs that I consider.
Another problem is clusters of vowels that usually don’t happen in Russian.
(Or, when they happen, Sokolov recommends skipping one of them.)
This clustering happens for words starting with “w” (undoubtedly a vowel too!) for example.
For these cases, an transitory dot (working clockwise / downwards instead of upwards for “z”) is put between vowels:

Another approach is using alternative vowel signs:



Sokolov explicitly claims that these alternative signs represent ě, ju, a, and e. But I’m ready to extend them to e/jo, u, and ja. Because Každan does merge these letters, unlike Sokolov.
So now when I want to write a really annoying combination of “w” plus vowel. I can just write an alternative “u” and then a vowel. Nice flow!
So we have alternative representations for “a,” “e,” “u,” but not for “o” and “i.” Which is mostly fine, but irritating. Anyway, “a” is out of the way and can be used in English words. Which is a win!
Both Každan and Sokolov emphasize that diacritics are rare and mostly unnecessary.
But, for English transcription where “j” often follows a vowel, these are vital!
Thus I’ll list them here:

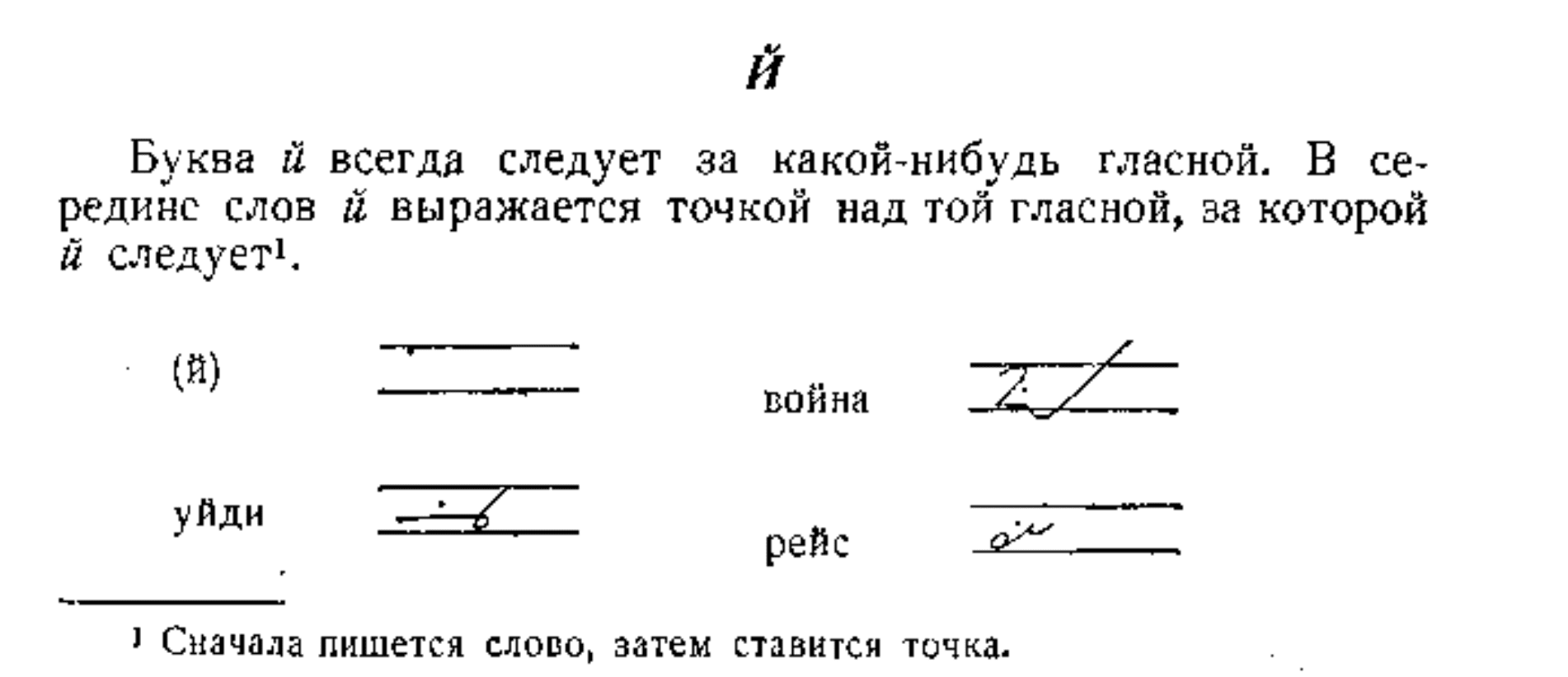

Full list of diacritic signs:
God, that’s so inconsistent. Especially with Každan introducing apostrophes. I’m going to stick to Sokolov’s dots.
So unoptimized nature of words and endings, and vowels—were my two biggest problems with using GESS for English. Otherwise, it’s fine.
What I ended up with is:
Which makes my setup incompatible with either Sokolov’s or Každan’s instruction material. Such is life.
But yeah, here is most of the system occupying 500-page books, in one web page. There are omissions, sure. But the contents of this page are roughly what I’m going to use everyday writing GESS. So if you read it, you are on the same page with me. Good luck in stenographing!